최근 삼성전자가 새로운 인공지능 연구하고 있다는 기사를 보았다. 이 기사에서 삼성전자는 Auto Capture based on VLM이라는 기술을 개발하고 있다고 한다. https://www.ebn.co.kr/news/articleView.html?idxno=1669280
[단독] "손흥민 골 넣을때 찍어줘"…삼성전자, AI로 카메라 혁신 - 이비엔(EBN)뉴스센터
특정 순간을 음성으로 명령하면 인공지능(AI)이 스스로 판단해 사진을 찍어주는 차세대 이미지 센서 기술을 삼성전자가 개발 중인 것으로 파악됐다. 이 기술이 상용화
www.ebn.co.kr
이 기술은 사용자가 음성으로 말하는 어느 한 순간을 카메라가 자동으로 찍어주는 기술이라고 한다. 예를 들어, "새가 날아가는 순간을 포착해줘"라고 말하면, 그 순간을 카메라가 포착하도록 하는 인공지능 기술이라고 한다.
이런 기술이 나름 신선하기도 하면서도 아직 어떻게 기술 개발이 이뤄져 있는지 공개되지 않아 흥미와 궁금증을 더하는 기술로 글쓴이에게는 느껴졌다.
그래서 이번 포스트에서는 기사의 설명을 듣고 아래의 사항들을 고려하여 원리를 대략적으로 추측해 볼 것이다.
- Auto Capture based on VLM의 구조가 어떻게 돼 있을지
- 데이터셋은 어떻게 구성돼 있을지
- 학습 과정은 어떻게 돼 있을지
추측되는 여러 모델 구조
이 기술의 입력은 동영상과 음성 데이터라고 추측 할 수 있다. 여기서 동영상은 시간에 따른 이미지로 해석할 수 있기에 입력은 여러 이미지와 음성이라고 할 수 있다. 두 가지의 서로 다른 데이터를 다루기에 multi-modal 방식으로 모델을 구성해야할 것이며, 대표적으로는 이미지와 글자를 처리할 수 있는 VLM (Vision Language Model) 등이 있다.
하지만, VLM의 경우, 이미지와 글자를 받는 구조지 음성을 받는 구조는 아니기에 VLM을 그대로 사용하기에는 무리가 있을 것으로 생각된다. 그렇다면, STT(Speech to Text) 모델을 중간에 도입하면 어떨까? 즉, 다음과 같은 시나리오를 생각할 수 있다.
- 우선 음성 데이터를 STT AI를 사용하여 문자로 변환한다.
- 변환된 문자와 이미지(들)를 AI의 입력으로 넣어 처리한다.

위의 시나리오 1은 그럴듯해 보이지만, 문자로 변환한다는 단계가 있다는 점이 인공지능 연구자로써 마음에 걸린다. 인공지능 모델을 합성할 때, 위와 같은 방식을 사용할 수도 있지만, 인공지능의 내부값(latent variable)을 활용하는 것이 일반적이라고 할 수 있다. 간단히 예를 들어, 사람 A과 같이 작업할 때 대화하는 것보단 텔레파시 같이 생각 자체를 읽는 것이 더 나은 작업 효율 증가로 이뤄지는 것으로 생각해 볼 수 있다.
즉, 위의 그림에서 조금 변영하여 두 모델을 정말로 하나의 모델로 통합할 수 있을 것이다.

STT AI와 VLM의 경우, 처음부터 학습시키는 방식보다는, 이미 대규모 데이터로 잘 학습된 모델을 미세조정(fine-tuning)하는 방식으로 모델을 학습시키지 않을까 추측해 본다. 이 시나리오 2는 음성에 해당되는 정보가 이미지에 있는지 없는지 등의 정보를 AI가 분석할 것으로 생각해 볼 수 있다. 즉, 실시간으로 들어오는 여러 이미지들을 매번 STT AI로 변환된 음성 정보와 비교할 것이다.
이 외에 다른 구조는 무엇을 생각해 볼 수 있을까? 위의 시나리오 2는 단일 이미지를 받는 형태이다. 하지만, 우리가 받는 데이터는 여러 이미지인 동영상이기에 이미지 여러 장을 받는 시나리오도 생각해 볼 수 있다. 아래 그림을 살펴보자.
이 모델은 세 개의 이미지 데이터와 한 개의 음성 데이터를 입력으로 받고 세 개의 이미지 중간 데이터와 한 개의 음성 데이터를 만들어 낸다. 그 다음 유사도 측정 알고리즘으로 하나의 음성이 세 개의 이미지 중 어느 것과 가장 유사한지를 점수로 나타내고 있다.
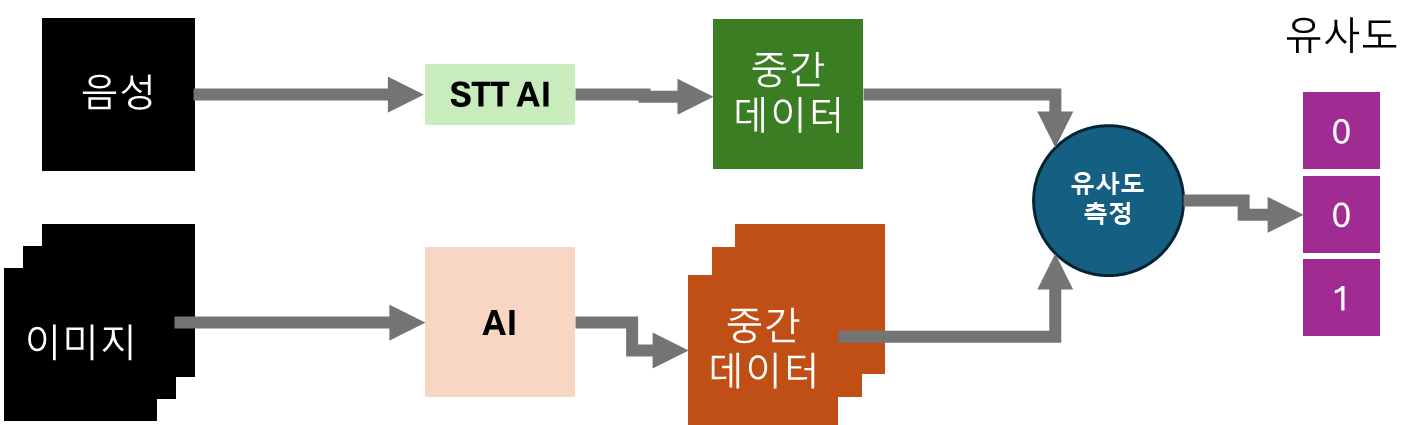
인공지능 연구자 입장에서는 시나리오 3가 다양한 학습 기법을 적용하기에 적합한 구조가 아닌가 생각한다.
추측되는 데이터셋 형태
데이터셋은 학습 관점에서 입력과 정답에 해당되는 데이터가 존재할 것이다. 입력은 동영상(시간에 따른 여러 이미지)와 그에 대응되는 하나의 음성 데이터가 있을 것이다. 그리고 정답 데이터는 그 여러 장의 이미지의 개수에 맞게 어느 타이밍에 음성 명령에 해당하는 정보가 이미지에 있는지를 나타내는 정보가 들어 있을 것이다. 정보가 있으면 1 없으면 0 이런 방식이며, 이미지 개수와 동일하게 존재할 것이다.
즉, 이미지가 3장(동영상 프레임이 3) 있고, 음성 정보가 2 ~ 3 프레임에 존재한다면 정답 데이터는 [0, 1, 1]로 돼 있을 것이다.
다양할 것으로 추측되는 학습 방식
워낙 다양한 학습 방법론이 존재하는 현재이다. Supervised Learning부터 시작해서 Self-Supervised Learning 등이 있을 것이다. 이 방법론들은 모델의 형태에 따라 달라지며, 여기서는 시나리오 1&2 그리고 3에서 적용해 볼 수 있는 아이디어를 간단히 알아보겠다.
시나리오 1&2
- Supervised learning
- 우선 직접적으로는 supervised learning으로 모델을 학습시키는 경우가 있을 것이다. 음성 정보가 이미지에 들어 있다면 1로 예측하도록 아니면 0으로 예측하는 단순한 방식이다. 하지만, 이 방식에는 단점이 있는데, 바로 데이터의 불균형성이다. 단순히 생각해 보아도, "새가 날아가는 순간을 포착해줘"라는 명령에서 "날아가는 순간"에 대한 이미지 프레임은 몇 장 안 될 것이다. 즉, 긴 동영상(여러 이미지) 시간 속 음성 정보가 이미지에 속하는 순간은 얼마 안 되기에, 정답 데이터가 대부분 0일 것이다. 흔히 말하는 data imbalance 문제이며 이 때는 supervised learning 방식이 효과적이지 못하다.
- Contrastive learning
- 그 다음으로 생각해 볼 수 있는 것은 self-supervised learning 기법 중 하나인 contrastive learning이다. 이 방식으로 pre-training을 진행하여 어느정도 데이터 자체에 대한 모델의 성능을 키워볼 수도 있을 것이다. 하지만 여전히 data imbalance 문제는 존재.
- GAN
시나리오 3
- Supervised learning
- 마찬가지로 시나리오 3도 supervised learning 방식으로 학습시켜볼 수 있을 것이다.
- Self-supervised learning
- 이미지 중간 데이터에는 분명 음성 정보가 들어 있는 중간 데이터와 그렇지 않은 데이터가 있을 것이다. 이 두 중간 데이터를 서로 멀게 그리고 각각의 중간 데이터끼리는 가깝게 학습한다면, 모델의 표현력을 향상시킬 수 있을 것이다.
- 이상 탐지 (Anomaly detection)
- 시간에 따른 여러장의 이미지는 결국 시간 데이터라고 볼 수 있다. 만약 음성에 맞는 특정 이벤트를 anomaly라고 여긴다면, 시계열 분야의 anomaly detection 방식을 사용해 볼 수도 있을 것이다.
- GAN
잡담
사실 어느 시나리오가 되었든 상관은 없다. 삼성전자가 목표한 바인 on-device AI를 추구하려면 성능과 모델 크기 그리고 추론 시간 등 사이의 타협이 있을 수밖에는 없다. 앞서 말한 시나리오 1&2는 한 번에 하나의 이미지만 처리하기에 병렬처리 성능이 부족한 환경에서는 적합할 수 있다. 반대로 시나리오 3는 여러 이미지를 한 번에 처리하기 때문에 병렬처리 성능이 뛰어난 환경에서 적합할 수 있다. 시나리오 1&2는 한 번에 하나의 이미지만 처리하기 때문에 메모리가 적게 들 것이다. 반대로 시나리오 3는 여러 이미지를 한 번에 처리하기 떄문에 메모리가 배로 들 것이다.
마치며
하나의 기술 설명을 기반으로 여러가지 추측을 해보며 시나리오를 구성해 보았다. 이렇게 여러 가능성의 시나리오와 학습 방법들 그리고 그 들 사이의 trade-off가 존재하며 이를 on-device에 올리는 것은 쉽지 않으며 도전적인 과제이다. 앞으로의 삼성전자가 이를 어떻게 해결해 나아갈 것이며, 그 기술이 적용된 우리 사회는 어떻게 변해 있을지 기대된다.
'인공지능 이야기' 카테고리의 다른 글
| 피지컬 AI: 육체적 노동도 이젠 인공지능의 영역으로. (0) | 2025.12.11 |
|---|---|
| 에이전틱 AI 시대, 당신의 생상성은 10배가 될 수 있을까? (0) | 2025.12.10 |
| 산불과 인공지능 (1) | 2025.03.25 |
| ChatGPT 성능 올리는 Chain of Thought 프롬프트 방법? (6) | 2025.01.08 |
| 인공지능 대학원생이 보는 2025 AI 트렌트? (8) | 2025.01.05 |

